V Data Collect provádíme každý měsíc výzkum, jehož cílem je zachytit pohled vybraného vzorku obyvatel na celkovou hospodářskou situaci státu a finanční situaci českých domácností. Sběr dat probíhá na reprezentativním výběrovém souboru 1000 respondentů. Naší cílovou skupinou je populace ČR ve věku 15 a více let. Voláme na náhodně generovaná telefonní čísla prostřednictvím pokročilé technologie CATI. Ptáme se i na kvótní otázky a to pohlaví, věk, region a velikost místa bydliště. Sběr dat probíhá v souladu s pravidly Sdružení agentur pro výzkum trhu a veřejného mínění SIMAR, jehož jsme součástí.
Ze získaných dat z období od května 2020 do října 2022 jsme připravili několik grafů, které hospodářskou a finanční situaci přehledně znázorňují.
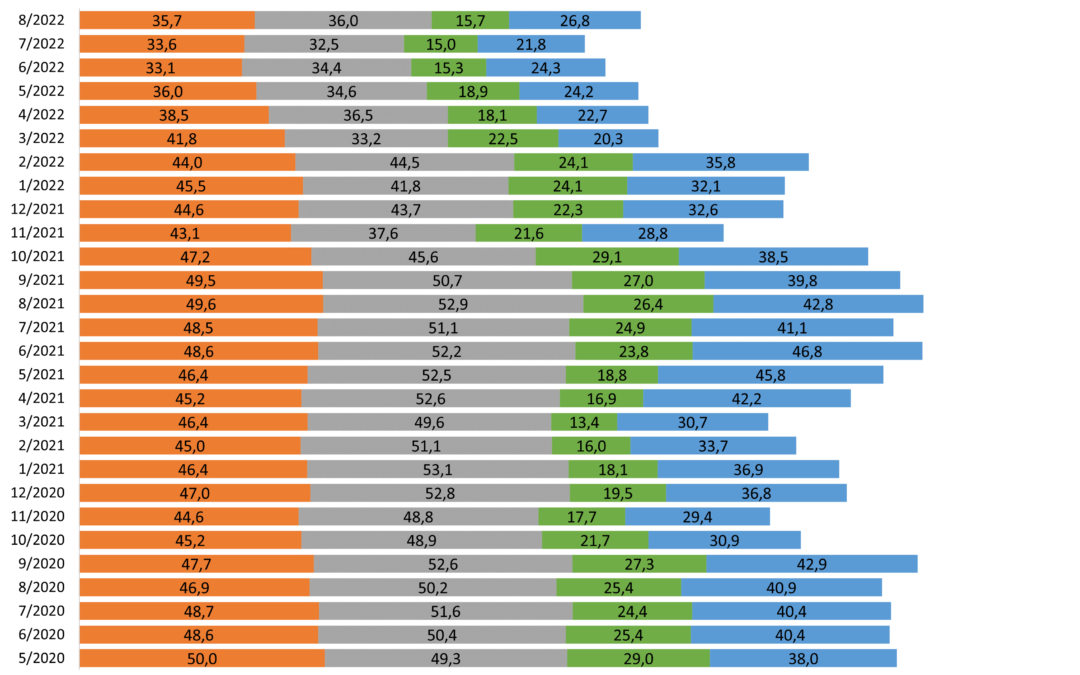
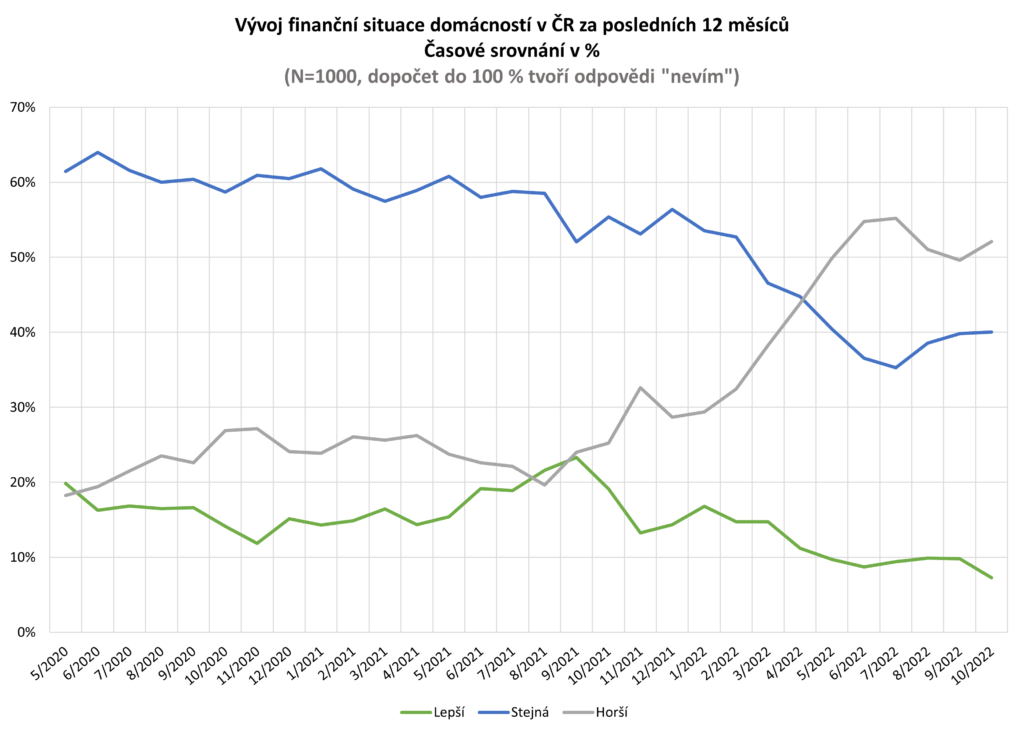
Skutečná změna finanční situace domácnosti v ČR
Na otázku: „Jak se změnila finanční situace Vaší domácnosti v průběhu minulých 12 měsíců? Je dnes lepší, horší nebo asi stejná?“ odpovídalo 1000 náhodně vybraných respondentů.
Zdroj: sběr dat od 5/2020 do 10/2022, telefonické dotazování náhodně generovaných čísel
Poznámka: kategorie „lepší“ je součtem kategorií „podstatně lepší“ a „o něco lepší“, kategorie „horší“ je součtem kategorií „o něco horší“ a „podstatně horší“. Dopočet do 100 % tvoří odpovědi „nevím“.
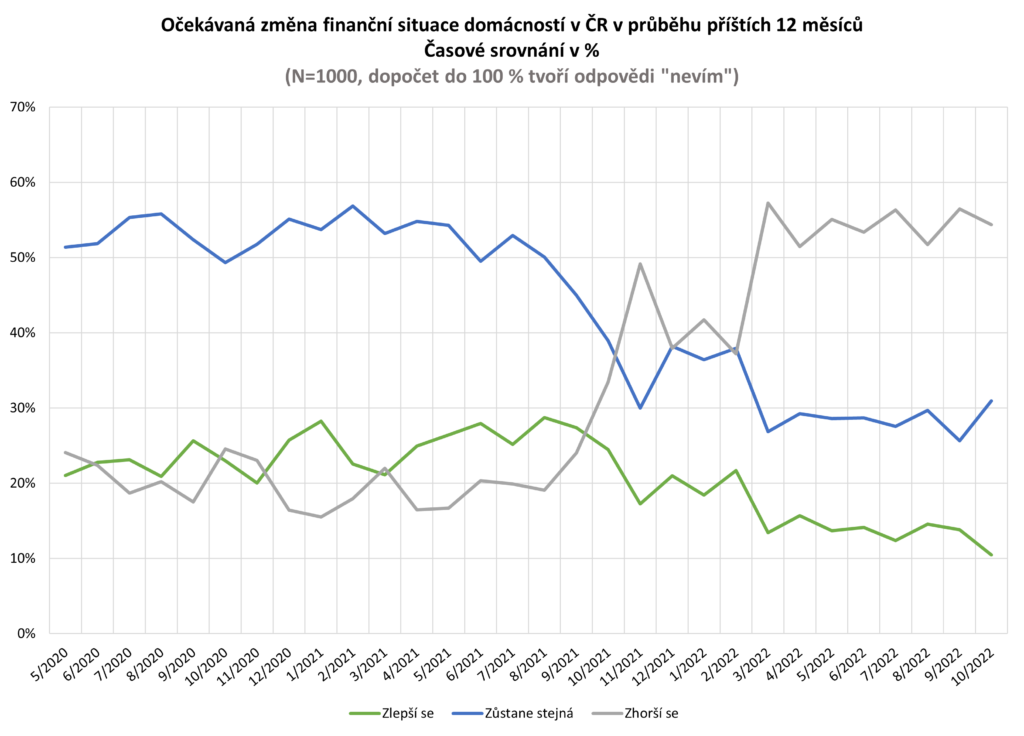
Očekávaná změna finanční situace domácnosti v ČR
Na otázku: „Jak očekáváte, že se změní finanční situace Vaší domácnosti v průběhu příštích 12 měsíců?“ odpovídalo 1000 náhodně vybraných respondentů.
Zdroj: sběr dat od 5/2020 do 10/2022, telefonické dotazování náhodně generovaných čísel
Poznámka: kategorie „zlepší se“ je součtem kategorií „podstatně zlepší“ a „o něco se zlepší“, kategorie „zhorší se“ je součtem kategorií „o něco se zhorší“ a „podstatně se zhorší“. Dopočet do 100 % tvoří odpovědi „nevím“.
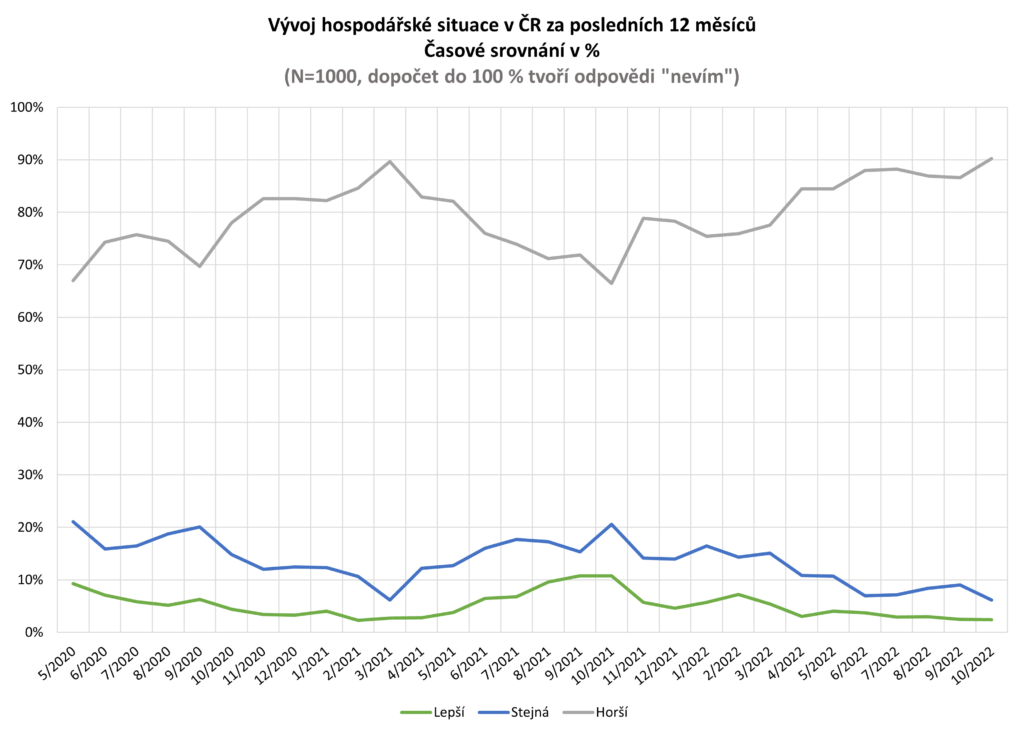
Skutečná změna hospodářská situace v ČR
Na otázku: „Jak si myslíte, že se změnila hospodářská situace v ČR v porovnání se situací před 12 měsíci?“ odpovídalo 1000 náhodně vybraných respondentů.
Zdroj: sběr dat od 5/2020 do 10/2022, telefonické dotazování náhodně generovaných čísel
Poznámka: kategorie „lepší“ je součtem kategorií „podstatně lepší“ a „o něco lepší“, kategorie „horší“ je součtem kategorií „o něco horší“ a „podstatně horší“. Dopočet do 100 % tvoří odpovědi „nevím“.
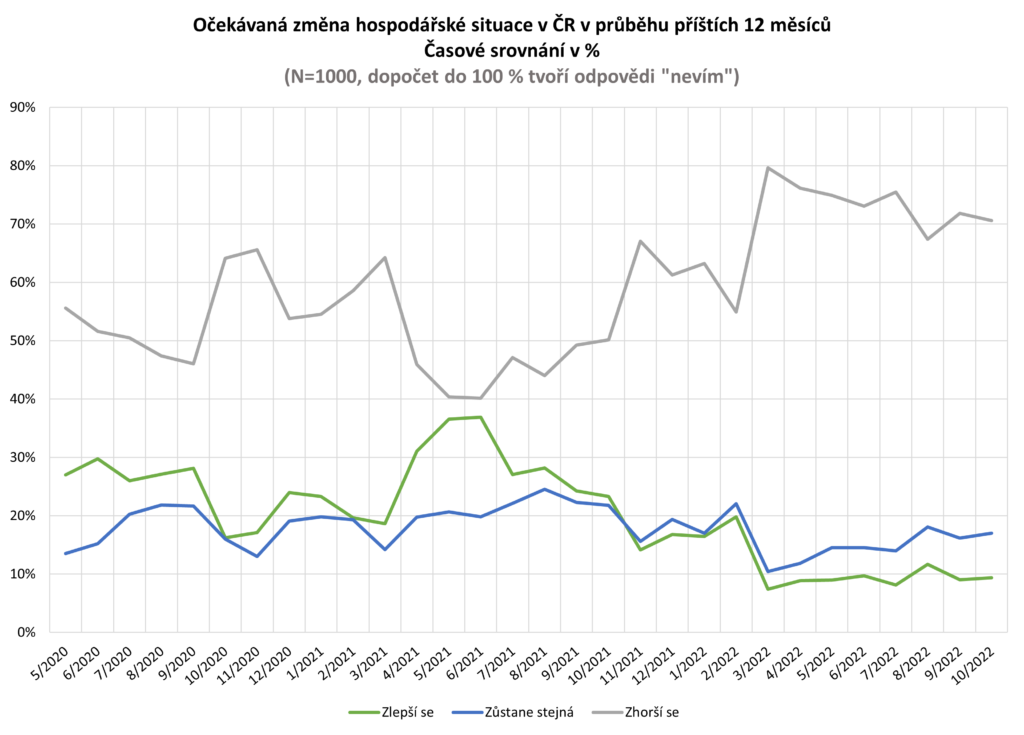
Očekávaná změna hospodářská situace v ČR
Na otázku: „Jak očekáváte, že se bude vyvíjet hospodářská situace v České republice v příštích 12 měsících?“ odpovídalo 1000 náhodně vybraných respondentů.
Zdroj: sběr dat od 5/2020 do 10/2022, telefonické dotazování náhodně generovaných čísel
Poznámka: kategorie „zlepší se“ je součtem kategorií „podstatně zlepší“ a „o něco se zlepší“, kategorie „zhorší se“ je součtem kategorií „o něco se zhorší“ a „podstatně se zhorší“. Dopočet do 100 % tvoří odpovědi „nevím“.
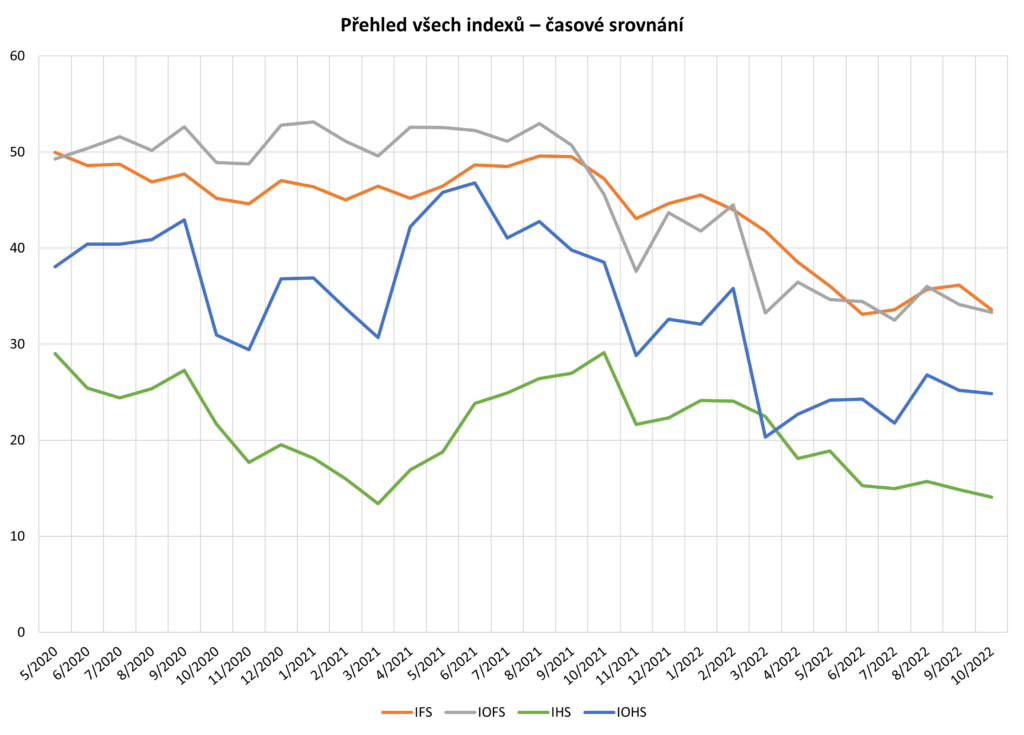
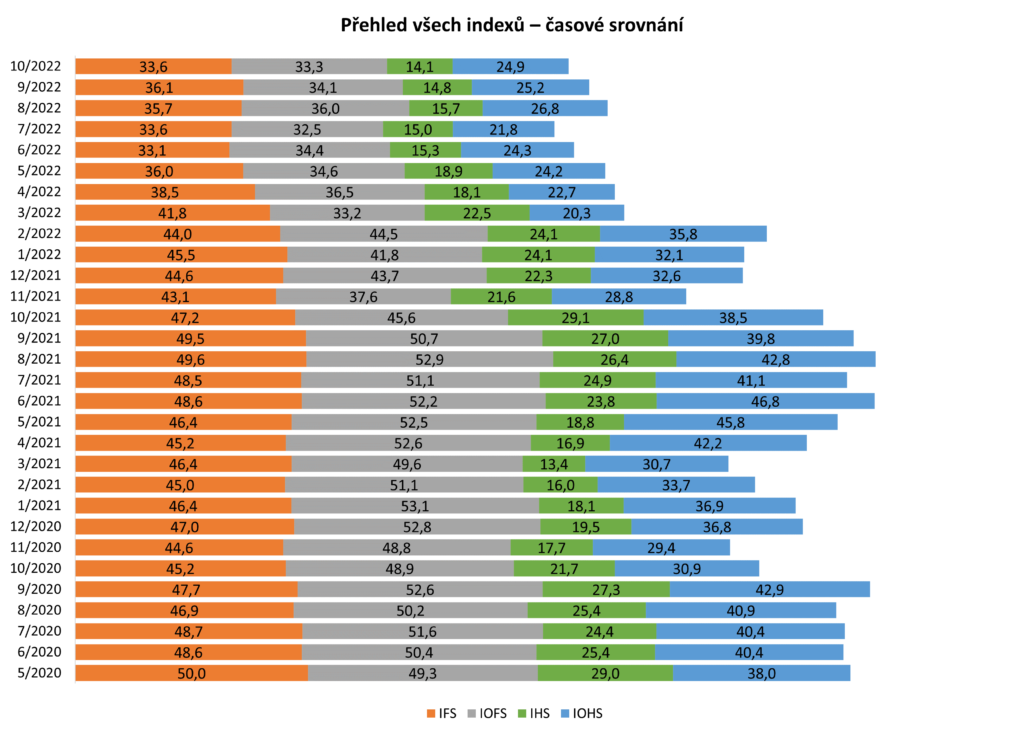
Přehled všech indexů
Následující dva grafy zobrazují časové srovnání čtyř indexů, a to indexu finanční situace (IFS), indexu očekávané finanční situace (IOFS), indexu hospodářské situace (IHS) a indexu očekávané hospodářské situace (IOHS).
Zdroj: sběr dat od 5/2020 do 10/2022, telefonické dotazování náhodně generovaných čísel
Zdroj: sběr dat od 5/2020 do 10/2022, telefonické dotazování náhodně generovaných čísel
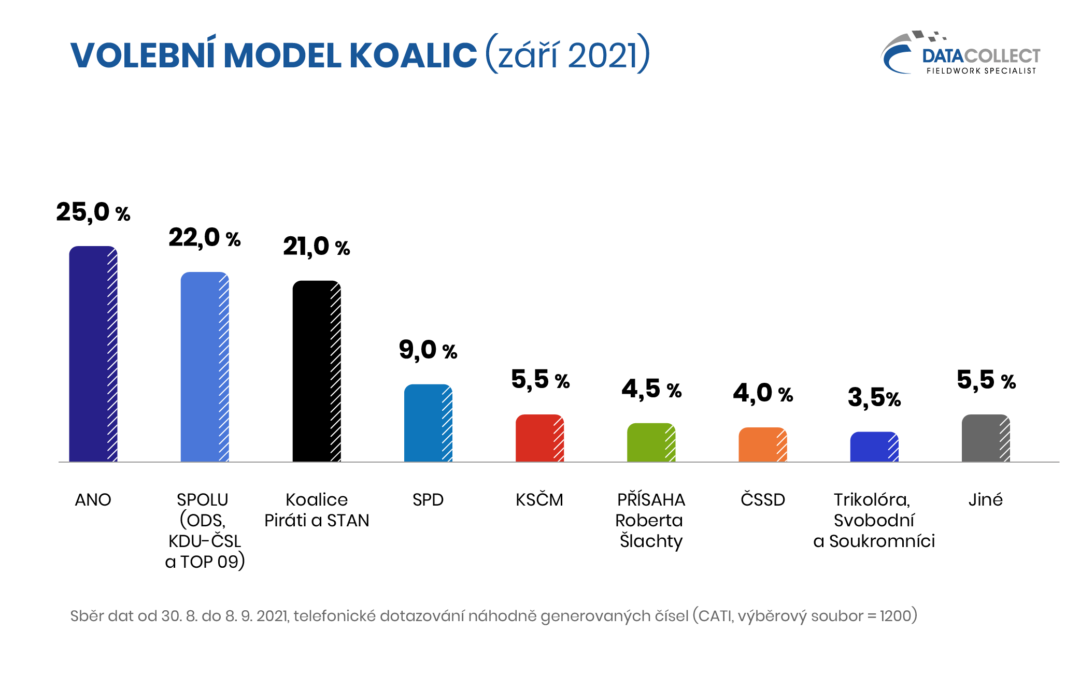
Data Collect na přelomu srpna a září provedl předvolební výzkum. Pro sběr dat byla využita pokročilá technologie CATI. Společnost Data Collect je řádným členem Sdružení agentur pro výzkum trhu a veřejného mínění SIMAR. Ze získaných dat jsme zpracovali volební model, pro případ zachování ohlášených koalic.
Základní soubor: Oprávnění voliči v České republice starší 18 let, kteří splňují podmínky pro vstup do volebního modelu. Náhodným výběrem byl získán reprezentativní výběrový soubor 1200 rozhovorů, z nichž do volebního modelu vstupuje 876 respondentů. Jedná se o respondenty, kteří nevylučují svou účast ve volbách a nepovažují za pravděpodobné, že volbu své preferované strany změní. Dotazování probíhalo ve dnech 30. 8. až 8. 9. 2021 prostřednictvím technologie CATI.
Poznámka: Zobrazeny jsou strany a koalice se současným ziskem alespoň 2 %. Statistická chyba volebního modelu u jednotlivých stran a koalic se pohybuje v rozmezí ±1,0 p. b. (strana nebo koalice s nízkým ziskem) až ±3,1 p. b. (strana nebo koalice s vysokým ziskem).
Další informace k provedenému šetření se dozvíte v závěrečné zprávě.
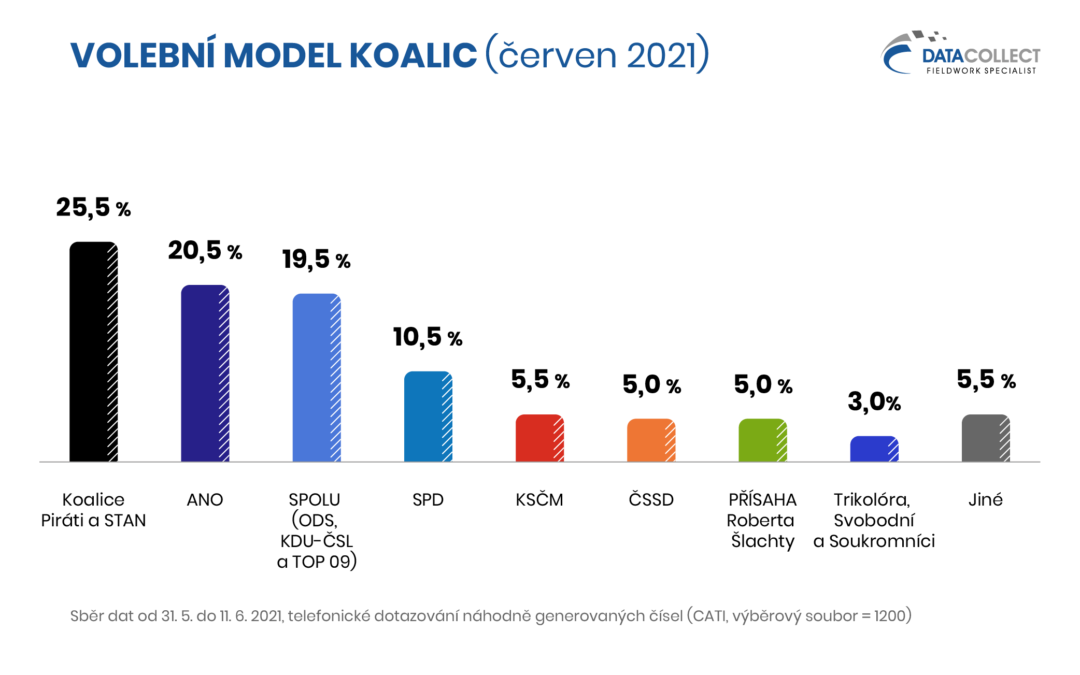
Data Collect v červnu provedl předvolební výzkum. Pro sběr dat v době nouzového stavu využil pokročilé technologie CATI pro volání z domova. Společnost Data Collect je řádným členem Sdružení agentur pro výzkum trhu a veřejného mínění SIMAR. Ze získaných dat jsme zpracovali dva volební modely, pro případ zachování ohlášených koalic a pro případ kandidatury samostatných stran.
Základní soubor: Oprávnění voliči v České republice starší 18 let, kteří splňují podmínky pro vstup do volebního modelu. Náhodným výběrem byl získán reprezentativní výběrový soubor 1200 rozhovorů, z nichž do volebního modelu vstupuje 882 respondentů. Jedná se o respondenty, kteří nevylučují svou účast ve volbách a nepovažují za pravděpodobné, že volbu své preferované strany změní. Dotazování probíhalo ve dnech 31. 5. až 11. 6. 2021 prostřednictvím technologie CATI.
Poznámka: Zobrazeny jsou strany se současným ziskem alespoň 2 %; výsledky jsou zaokrouhlovány na půl procenta. Statistická chyba volebního modelu u jednotlivých stran se pohybuje v rozmezí ±1,0 p. b. (strana s nízkým ziskem) až ±3,1 p. b. (strana s vysokým ziskem).
Základní soubor: Oprávnění voliči v České republice starší 18 let, kteří splňují podmínky pro vstup do volebního modelu. Náhodným výběrem byl získán reprezentativní výběrový soubor 1200 rozhovorů, z nichž do volebního modelu vstupuje 910 respondentů. Jedná se o respondenty, kteří nevylučují svou účast ve volbách a nepovažují za pravděpodobné, že volbu své preferované strany změní. Dotazování probíhalo ve dnech 31. 5. až 11. 6. 2021 prostřednictvím technologie CATI.
Poznámka: Zobrazeny jsou strany se současným ziskem alespoň 2 %; výsledky jsou zaokrouhlovány na půl procenta. Statistická chyba volebního modelu u jednotlivých stran se pohybuje v rozmezí ±1,0 p. b. (strana s nízkým ziskem) až ±3,1 p. b. (strana s vysokým ziskem).
Další informace k provedenému šetření se dozvíte v závěrečné zprávě.
Data Collect v květnu provedl předvolební výzkum. Pro sběr dat v době nouzového stavu využil pokročilé technologie CATI pro volání z domova. Společnost Data Collect je řádným členem Sdružení agentur pro výzkum trhu a veřejného mínění SIMAR. Ze získaných dat jsme zpracovali dva volební modely, pro případ zachování ohlášených koalic a pro případ kandidatury samostatných stran.
Základní soubor: Oprávnění voliči v České republice starší 18 let, kteří splňují podmínky pro vstup do volebního modelu. Náhodným výběrem byl získán reprezentativní výběrový soubor 1200 rozhovorů, z nichž do volebního modelu vstupuje 875 respondentů. Jedná se o respondenty, kteří nevylučují svou účast ve volbách a nepovažují za pravděpodobné, že volbu své preferované strany změní. Dotazování probíhalo ve dnech 3. 5. až 7. 5. a 17. 5. až 21. 5. 2021 prostřednictvím technologie CATI.
Poznámka: Zobrazeny jsou strany se současným ziskem alespoň 2 %. Statistická chyba volebního modelu u jednotlivých stran se pohybuje v rozmezí ±1,0 p. b. (strana s nízkým ziskem) až ±3,1 p. b. (strana s vysokým ziskem).
Základní soubor: Oprávnění voliči v České republice starší 18 let, kteří splňují podmínky pro vstup do volebního modelu. Náhodným výběrem byl získán reprezentativní výběrový soubor 1200 rozhovorů, z nichž do volebního modelu vstupuje 904 respondentů. Jedná se o respondenty, kteří nevylučují svou účast ve volbách a nepovažují za pravděpodobné, že volbu své preferované strany změní. Dotazování probíhalo ve dnech 3. 5. až 7. 5. a 17. 5. až 21. 5. 2021 prostřednictvím technologie CATI.
Poznámka: Zobrazeny jsou strany se současným ziskem alespoň 2 %. Statistická chyba volebního modelu u jednotlivých stran se pohybuje v rozmezí ±1,0 p. b. (strana s nízkým ziskem) až ±3,1 p. b. (strana s vysokým ziskem).
Další informace k provedenému šetření se dozvíte v závěrečné zprávě.
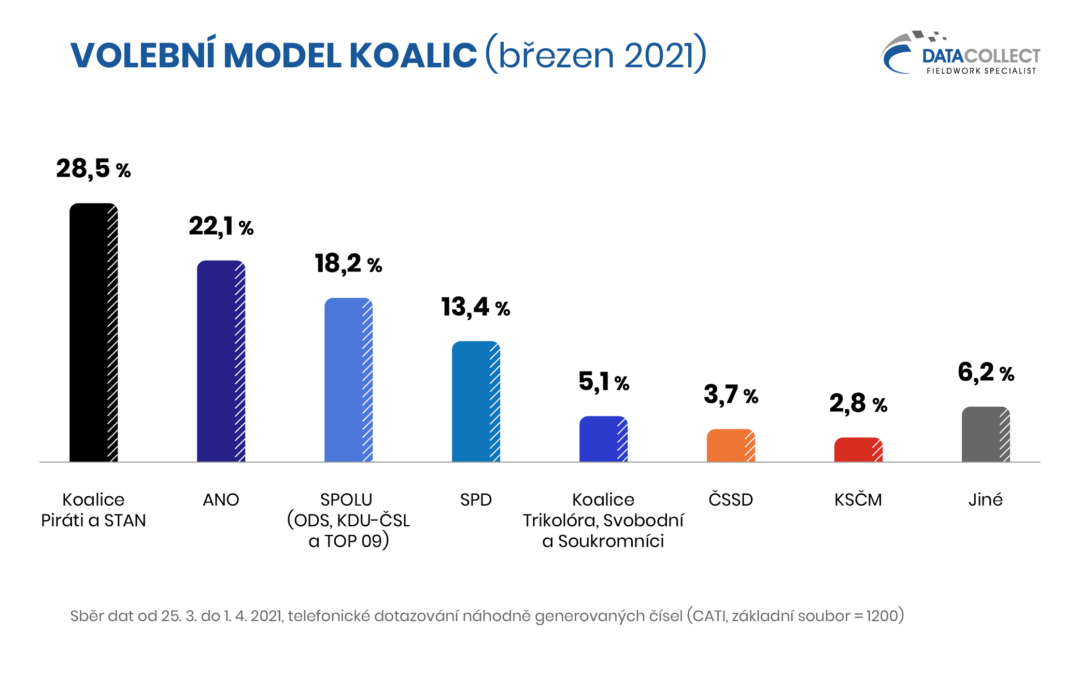
Data Collect v březnu provedl předvolební výzkum. Pro sběr dat v době nouzového stavu využil pokročilé technologie CATI pro volání z domova. Kvalita a věrohodnost sběru byla kontrolována Sdružení agentur pro výzkum trhu a veřejného mínění SIMAR. Ze získaných dat jsme zpracovali dva volební modely, pro případ zachování ohlášených koalic a pro případ kandidatury samostatných stran.
Základní soubor: Oprávnění voliči v České republice starší 18 let, kteří splňují podmínky pro vstup do volebního modelu. Náhodným výběrem byl získán reprezentativní výběrový soubor 1200 rozhovorů, z nichž do volebního modelu vstupuje 881 respondentů. Jedná se o respondenty, kteří nevylučují svou účast ve volbách a nepovažují za pravděpodobné, že volbu své preferované strany změní. Dotazování probíhalo ve dnech 25. 3. až 1. 4. 2021 prostřednictvím technologie CATI.
Poznámka: Zobrazeny jsou strany se současným ziskem alespoň 2 %. Statistická chyba volebního modelu u jednotlivých stran se pohybuje v rozmezí ±1,0 p. b. (strana s nízkým ziskem) až ±3,1 p. b. (strana s vysokým ziskem).
Základní soubor: Oprávnění voliči v České republice starší 18 let, kteří splňují podmínky pro vstup do volebního modelu. Náhodným výběrem byl získán reprezentativní výběrový soubor 1200 rozhovorů, z nichž do volebního modelu vstupuje 919 respondentů. Jedná se o respondenty, kteří nevylučují svou účast ve volbách a nepovažují za pravděpodobné, že volbu své preferované strany změní. Dotazování probíhalo ve dnech 25. 3. až 1. 4. 2021 prostřednictvím technologie CATI.
Poznámka: Zobrazeny jsou strany se současným ziskem alespoň 2 %. Statistická chyba volebního modelu u jednotlivých stran se pohybuje v rozmezí ±1,0 p. b. (strana s nízkým ziskem) až ±3,1 p. b. (strana s vysokým ziskem).
Další informace k provedenému šetření se dozvíte v závěrečné zprávě.
Již je tomu rok, co se světoví ekonomové zabývají tím, jak pandemie COVID-19 ovlivňuje světové trhy, která odvětví to odnesou nejvíce, pro která se virus stal příležitostí a především predikcemi, jak dlouho se svět z této situace bude vzpamatovávat a kdy se vrátí do normálu. Dřívější čisté věštění z křišťálové koule s přibývajícím časem, a tedy i zkušeností, od propuknutí pandemie, dostává konkrétnější rysy na základě již dostupných čísel. Disbalanc napříč odvětvími ekonomiky je veliký.
Pojďme nezobecňovat a podívat se, jak je na tom „naše“ odvětví, tedy průzkum trhu a marketingový výzkum.
Také v sektoru průzkumu trhu a marketingového průzkumu je využíváno online i offline metod sběru dat. Poslední dobou zaznamenáváme čím dál tím větší využití online sběru dat. To je způsobeno tlakem na rychlost sběru, která je obecně vyvolaná potřebou co možná nejaktuálnějších dat.
Data Collect dlouhodobě sleduje trendy v průzkumu trhu a marketingovém výzkumu, především v USA, kde jsou v tomto odvětví velmi napřed. Nástroje na online sběr dat jsme tak měli připravené již dávno před příchodem pandemie.
Technologické možnosti, které již umožňují dělat online i kvalitativní sběr dat, jako například Collabito, jsou v kurzu více, než kdy předtím. Pandemie COVID-19 nevyhnutelnou transformaci odvětví průzkumu trhu pouze urychlila.
Online výzkum (CAWI) není jedinou online metodou sběru dat, je však čím dál populárnější a v současnosti nejvíce zastoupenou. Je rychlá, procento online populace se neustále zvyšuje a v neposlední řadě je velmi „social distancing friendly“. Především to z ní v loňském roce (a také letos) dělá favorita. Stejné platí i pro telefonický průzkum. Pro firmu, jako je ta naše, se toho tedy, kromě přesunutí všech našich tazatelů na volání z domova (tzv. home CATI), mnoho nezměnilo. A naše kapacita zůstala bez omezení.
Jsou samozřejmě metodiky sběru dat, pro které by dlouho přetrvávající současná situace mohla být závažný problém. Řeč je o osobním dotazováním (F2F) nebo mystery shoppingu.
S pandemií přišly také některé příležitosti. Zrychlení migrace výzkumných projektů z tradičních metod do metod onlinových.Využití call-center pro pomoc s trasováním nemocných, podrobné studie mapující vliv nouzového stavu a jeho dopadu na společnost, jak vnímáme první, druhou vlnu, jak si vedeme finančně či psychicky ve srovnání s loňským rokem…atd.
Na blízký návrat do stavu, který jsme považovali před rokem za normální to nevypadá. Otázkou pak je, zdali je něco jako návrat do minulosti vůbec žádoucí. Spíš to nyní vypadá, že bude třeba se adaptovat na novou realitu a na změny zákaznického chování, které byly z části vynucené a z části přirozené.
My v Data Collectu s tím rádi pomůžeme, naše nástroje sběru dat jsou na novou realitu plně připraveny.
Zásady používání souborů cookie a zpracování osoobních údajů
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.












Nejnovější komentáře